
#28 - Beyond Data Warehouses: How Data Lakehouses Are Making Enterprise-Grade Analytics Accessible in 2025
The uncomfortable truth about data architecture decisions (and what works instead)

Read time: 4 minutes.
Hey Data Modernisers & AI Enablers,
When I first started building data pipelines 15 years ago, I thought I was doing everything right.
I was following enterprise ETL patterns, implementing robust data warehouses, and choosing the most proven technologies available.
But projects dragged on for months. Costs spiralled beyond budgets. Business users complained they still couldn't get insights.
After building pipeline after pipeline that worked technically but failed to meet business expectations, I started thinking maybe I was just bad at understanding what companies needed.
The truth was, we weren't building bad systems. We were solving today's problems with yesterday's architecture patterns.
Today's data engineer would run circles around a 2010s data engineer.
So today, I'm revealing why the most innovative companies are choosing data lakehouses over traditional approaches.
Ready? Let's go.
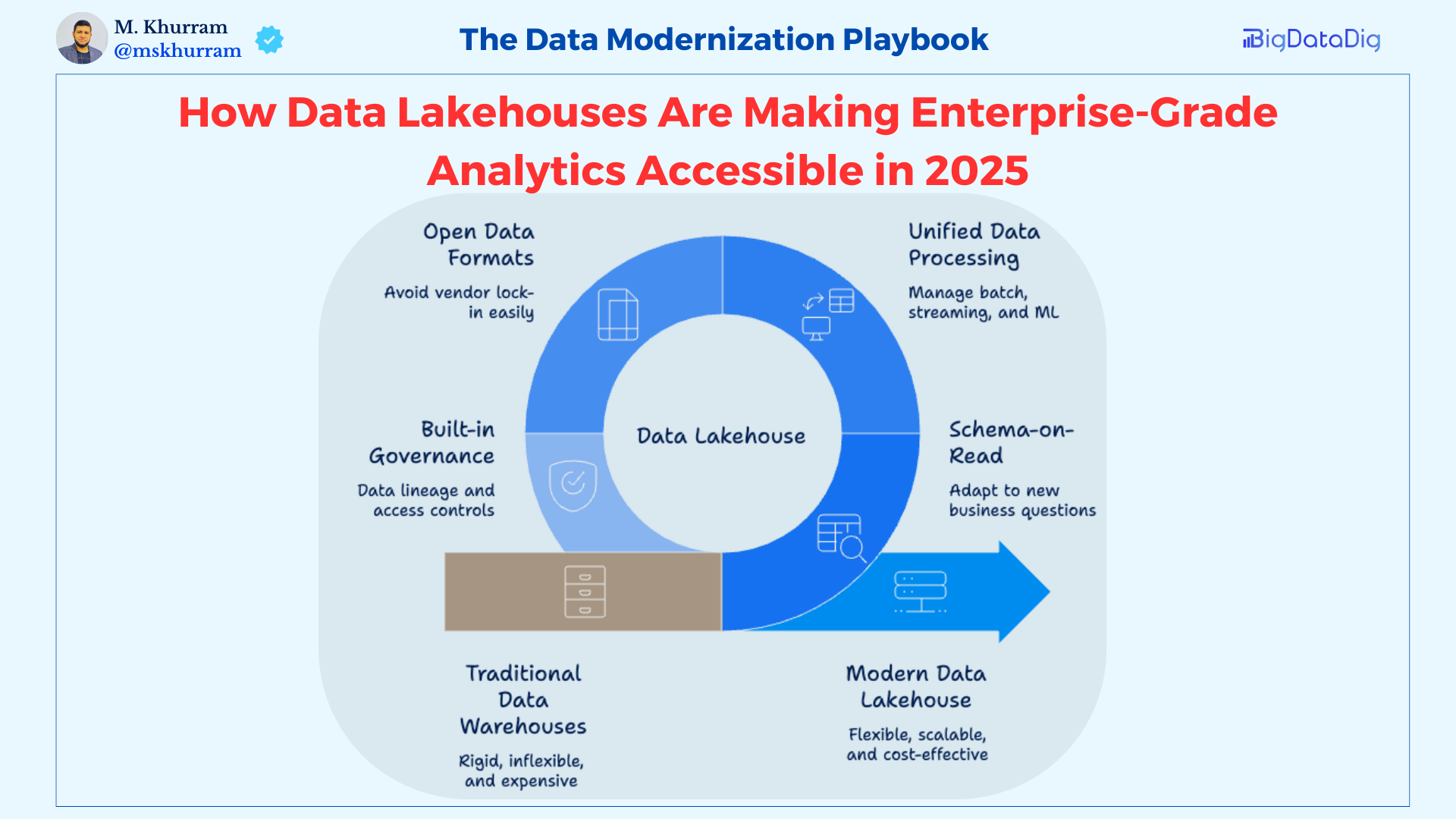
What Is a Data Lakehouse?
A data lakehouse combines data lake flexibility with data warehouse performance.
But here's what most explanations miss: it's not just a technical architecture, it's a business strategy.
Traditional warehouses were designed when data was predictable and structured. Customer records, sales transactions, and financial data; everything fit neatly into predefined schemas.
Today's reality is different.
You're dealing with website behaviour data, IoT sensor streams, social media interactions, and real-time application logs. Forcing this variety into rigid warehouse schemas is like trying to fit a river into a bathtub.
Pure data lakes created different problems. Without warehouse performance optimisations, teams ended up with massive storage systems they couldn't use for business decisions.
Data lakehouses solve both problems.
They store raw data in open formats like Parquet and Delta Lake, then add warehouse-like query engines on top. You get the flexibility to handle any data type with the performance to analyse architecture Principles That Matter
1. Schema-on-Read Flexibility
Traditional warehouses require you to define a data structure before storing data. If the business requirements change, you have to wait for weeks of schema modifications.
Lakehouses enable data storage first, allowing for structure to be applied when analysing data to adapt to new business questions without requiring architectural changes.
2. Unified Data Processing
Lakehouses manage batch processing, streaming, and machine learning on a single platform, rather than transferring data between systems for different use cases.
This eliminates data movement costs and complexity.
3. Open Data Formats
Your data lives in open formats like Parquet rather than on proprietary databases. There is no vendor lock-in, and you can access it with any compatible tool.
4. Built-in Governance
With Lakehouses, data lineage, access controls, and audit trails are essential features, not add-ons.
Lakehouse vs Warehouse: The Real Differences
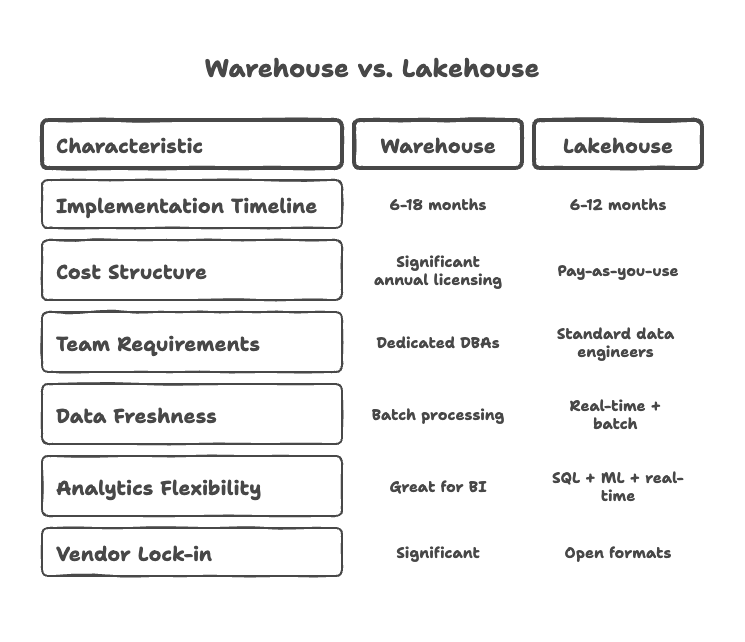
Implementation Timeline
Warehouse: 12-18 months, extensive upfront modelling required
Lakehouse: 6-12 months, iterative development approach
Cost Structure
Warehouse: Significant annual licensing costs, expensive scaling
Lakehouse: Pay-as-you-use, substantially lower total cost
Team Requirements
Warehouse: Dedicated DBAs, rigid change processes
Lakehouse: Standard data engineers, agile development
Data Freshness
Warehouse: Batch processing, daily/weekly updates
Lakehouse: Real-time streaming + batch processing
Analytics Flexibility
Warehouse: Great for BI, limited advanced analytics
Lakehouse: SQL analytics + ML + real-time processing
Vendor Lock-in
Warehouse: Significant due to proprietary formats
Lakehouse: Open formats, easier migration
The bottom line: medium-sized companies get enterprise capabilities without enterprise overhead.
Platform Reality Check: What Actually Works
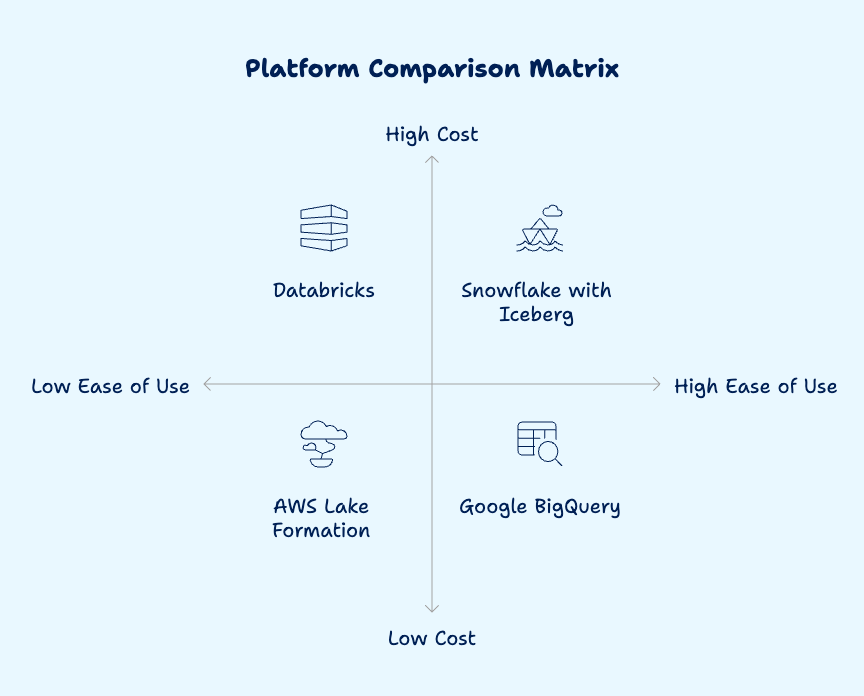
Tier 1: Production Ready
Databricks
Best for: Teams with technical depth, substantial budgets, and multiple data engineers
Reality: Excellent ML capabilities, requires optimisation
Snowflake with Iceberg
Best for: Warehouse transitions, operational simplicity priority
Reality: Higher per-query costs, lowest operational overhead
Tier 2: Cloud Native
AWS Lake Formation
Best for: AWS-committed orgs, variable workloads
Reality: Lowest cost, requires hands-on management
Google BigQuery
Best for: Analytics-heavy workloads, Google ecosystem
Reality: Great performance, expensive at high query volumes
3-Phase Implementation Strategy
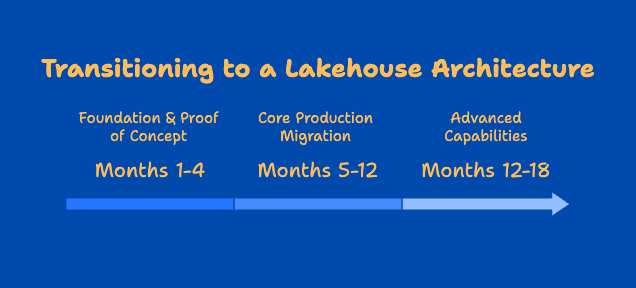
Phase 1: Foundation & Proof of Concept (Months 1-4)
Establish data governance frameworks and security policies before migrating any data.
Build one complete end-to-end use case that demonstrates clear business value. Choose something important enough to get attention but simple enough to execute well.
Focus: Prove the approach works and build team confidence
Phase 2: Core Production Migration (Months 5-12)
Migrate your most important reporting and analytics workloads while keeping existing systems running in parallel.
Start with business processes that have well-defined requirements and clear success criteria. Validate everything works before decommissioning legacy systems.
Focus: Replace existing capabilities with improved performance and reliability
Phase 3: Advanced Capabilities (Months 12-18)
Add machine learning, real-time streaming, and advanced analytics that weren't possible with your previous architecture.
Expand to more complex use cases and begin leveraging the complete flexibility of the lakehouse approach.
Focus: Deliver new business capabilities that justify the investment.
Critical Success Factors
Governance before technology - You can't organise with good technology
Start simple - Prove value with basics before complex analytics
Invest in training - Team capability determines platform success
Plan for culture change - Technical migration is 40%, adoption is 60%
Monitor costs actively - Cloud makes overspending easy without controls
When Lakehouse Makes Sense (And When It Doesn't)
Choose Lakehouse if you have:
Diverse data sources (APIs, files, streaming, databases)
Growing data volumes that your current system can't handle
Need for both structured reporting and exploratory analytics
Basic data engineering capabilities on your team
Desire to avoid vendor lock-in
Stick with your current approach if:
Your existing system efficiently meets all needs
Fewer than 3 people work with data regularly
Data is entirely structured and changes infrequently
Compliance mandates specific database technologies
Limited technical capabilities and training budget
Don't Set Data Goals. Build Data Systems.
While goals matter ("We want real-time analytics"), they won't move the needle. They only set the destination.
Focus on building systems that deliver incremental value every quarter and adapt as business needs evolve.
This transforms you into the data-driven organisation you aspire to be.
Onward and upward.
PS...If you're enjoying this newsletter, please consider referring this edition to a colleague who is struggling with data architectures and AI uncertainty.
And whenever you are ready, there are 3 ways I can help you:
Free Data Flow Audit - 60-minute deep-dive where we map your current data flows and identify precisely where chaos is killing your AI initiatives
Modular Pipeline Migration - Complete rebuild from spaghetti scripts to dbt + Airflow architecture that your AI systems can depend on
AI-Ready Data Platform - Full implementation of version-controlled, tested, modular data pipeline with real-time capabilities designed for production AI workloads
That’s it for this week. If you found this helpful, leave a comment to let me know ✊
About the Author
Khurram, founder of BigDataDig and a former Teradata Global Data Consultant, brings over 15 years of deep expertise in data integration and robust data processing. Leveraging this extensive background, he now specialises in organisational financial services, telecommunications, retail, and government sectors, implementing cutting-edge, AI-ready data solutions. His methodology prioritises value-driven implementations that effectively manage risk while ensuring that data is prepared, optimised, and advanced analytics.