
#18 - 5 Types of Technical Debt in Data Pipelines
Is your data pipeline becoming harder to manage? Technical debt might be the culprit

Hello Data Modernizers,
Data teams across industries make quick fixes and workarounds daily to keep data flowing. Each of these small compromises might seem inconsequential at the moment, but they accumulate into technical debt, the price you pay tomorrow for the shortcuts you take today.
In this week's newsletter, we're exploring the hidden technical debt lurking in your ETL processes, how to identify the warning signs before crisis strikes, and practical strategies for resolving these issues without disrupting your operations.
Let’s dive in.
What Exactly Is Technical Debt in Data Pipelines?
Technical debt in data pipelines refers to the compromises and shortcuts taken when building, managing, and maintaining your data flows. Much like the frog boiling in a pot, technical debt doesn't happen all at once – it's the cumulative result of small changes over time, as users make decisions that seem best for the immediate situation without considering long-term consequences.
While the concept of technical debt originated in software development, it manifests differently in the data world. Here's why data pipeline debt is particularly insidious:
It's often invisible until critical – Unlike application bugs that users report, data pipeline issues can lurk undetected for months.
It compounds quickly – Each transformation added to a pipeline creates dependencies that exponentially increase complexity.
It impacts the entire organization – Decision-making across departments halts when data pipelines fail.
It's resource-intensive to fix – Remediating ingrained data pipeline issues requires specialized skills and significant time.
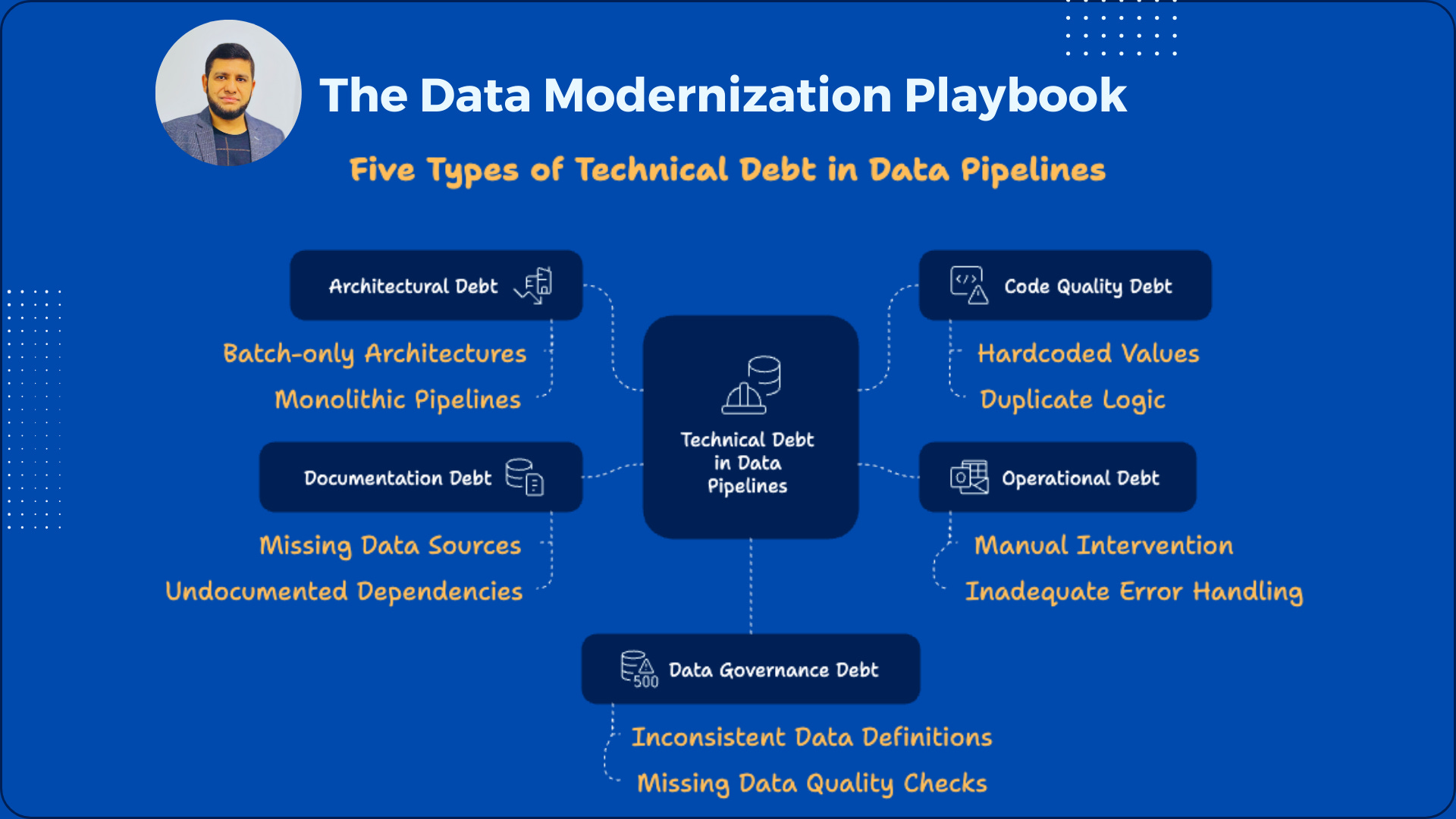
The Five Types of Technical Debt in Data Pipelines
Not all technical debt is created equal. Understanding the specific types affecting your pipelines is the first step toward resolution:
1. Architectural Debt
What it is:
Pipelines designed for yesterday's requirements rather than today's needs
Examples include:
Batch-only architectures that can't support real-time needs
Monolithic pipelines that should have been modular
On-premises designs awkwardly stretched to work in cloud environments
Real-world impact:
A media company continued using legacy batch ETL tools even as its business shifted to real-time streaming.
Competitors gained an advantage by delivering personalized content recommendations hours faster.
Business opportunities are lost due to the inability to adapt to changing market demands.
2. Code Quality Debt
What it is:
The transformation code was written hastily without proper review or testing
Signs include:
Hardcoded values and business rules
Duplicate logic across multiple pipelines
Complex, nested transformations without documentation
Lack of version control for pipeline code
Real-world impact:
A healthcare provider's billing analytics relied on hardcoded insurance rates buried in SQL
When rates changed, not all instances of hardcoded values were updated
Result: millions in undercharges before the error was discovered
3. Operational Debt
What it is:
Shortcuts in how pipelines are deployed, monitored, and maintained
Examples include:
Manual intervention is required for routine tasks
Inadequate error handling and alerting
Missing or incomplete monitoring
Lack of disaster recovery planning
Real-world impact:
One manufacturing company's data team manually restarted failed pipelines every morning.
No time allocated to implement proper error handling
Consumed 25% of a senior engineer's time for over two years
Opportunity cost: approximately $150,000
4. Documentation Debt
What it is:
Pipelines lack proper documentation, making each change a research project
Symptoms include:
Missing information on data sources and transformations
No data lineage tracking
Undocumented dependencies between pipelines
Lack of knowledge transfer processes
Real-world impact:
Teams struggle to understand what columns mean or what business logic was used.
Creates a terrible experience navigating the data warehouse
New analysts take months to become productive
Changes require extensive investigation before implementation
5. Data Governance Debt
What it is:
Governance is treated as an afterthought rather than a design principle
Appears as:
Inconsistent data definitions across pipelines
Missing or inadequate data quality checks
Unclear data ownership and responsibilities
Lack of compliance considerations in pipeline design
Real-world impact:
A financial services firm discovered that critical customer risk calculations were inconsistent across departments.
Resolving these inconsistencies required six months of dedicated cross-functional work
Regulatory compliance issues and potential penalties
Loss of trust in data-driven decision making
Case Study: From Data Pipeline Debt to Data-Driven Agility
One manufacturing company faced a critical situation with their ETL processes that had grown organically over 15 years, resulting in:
400+ separate data pipelines with unknown dependencies
Processing times increased from 2 hours to 14+ hours
Weekly pipeline failures requiring manual intervention
No single person understands the entire data flow
Inability to implement new analytics use cases
Rather than attempting a high-risk complete rebuild, they implemented a phased technical debt reduction approach:
Phase 1: Stabilize (3 months)
Comprehensive pipeline inventory and documentation
Implementation of monitoring and alerting
Critical fixes for frequently failing pipelines
Development of a technical debt remediation roadmap
Phase 2: Standardize (6 months)
Migration to a modern orchestration platform
Implementation of code and documentation standards
Creation of a central transformation repository
Development of automated testing frameworks
Phase 3: Modernize (Ongoing)
Incremental refactoring of critical pipelines
Introduction of real-time capabilities alongside batch
Migration of appropriate workloads to cloud platforms
Implementation of self-service data preparation tools
The Results:
70% reduction in pipeline failures
60% decrease in average processing time
40% reduction in cloud infrastructure costs
Ability to implement new analytics use cases in days rather than months
Most importantly, the company's leadership now views its data pipeline capabilities as a competitive advantage rather than a cost center.
The key is to start small, focus on measurable improvements, and build momentum toward a more comprehensive technical debt reduction program.
PS… If you're benefiting from these insights on the serverless data revolution, consider sharing this edition with a colleague struggling with traditional ETL issues. For every five referrals, I'll provide exclusive access to my 2025 AWS Glue Performance Optimization Playbook.
That’s it for this week. If you found this helpful, leave a comment to let me know ✊
About the Author
With 15+ years of experience implementing data integration solutions across financial services, telecommunications, retail, and government sectors, I've helped dozens of organizations implement robust ETL processing. My approach emphasizes pragmatic implementations that deliver business value while effectively managing risk.