
#15 - De-Risk Your ETL Migration: Tackling Documentation from Legacy to Modern
The Hidden Cost: How Undocumented Logic Sabotages Migration Success

Hello Data Modernizers,
The hidden crisis of undocumented ETL logic is costing businesses millions in migration delays and budget overruns. But there are proven, research-backed ways to tackle it.
Welcome to this week's edition. In this edition, we'll explore the real-world measurable impact of documentation debt, practical methodologies for reverse-engineering complex legacy rules, and how leading companies prevent documentation debt by building automated solutions into modern environments.
Let's dive in.
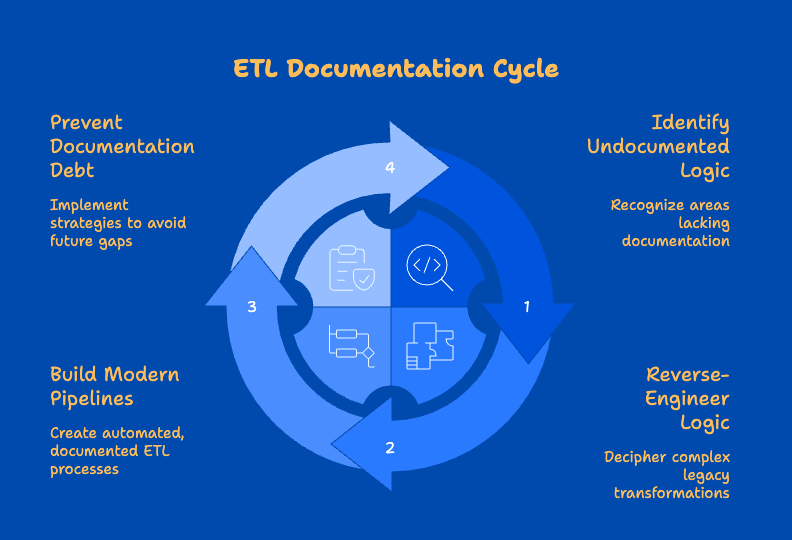
3 Methods To Rescue Your ETL Migration Even When Documentation Is Non-Existent
1. Implement a Tiered Documentation Recovery Strategy
It’s a common challenge in large ETL migrations: facing large amounts of poorly documented or understood transformation logic. Trying to document everything upfront is often impractical and delays critical progress. Industry best practices and standard risk management principles strongly advocate for prioritization.

A highly effective approach is implementing a Tiered Documentation Recovery Strategy. Based on experience navigating these challenges within major financial and retail organizations here in New Zealand, this involves categorizing legacy transformations based on business criticality:
Tier 1 (Critical): Transformations directly impacting core financials, regulatory compliance, or essential customer-facing functions.
Tier 2 (Important): Logic supporting significant internal business processes or reporting.
Tier 3 (Standard): All other transformations with lower immediate impact.
By intensely focusing expert resources on understanding and documenting Tier 1 first, project teams consistently achieve significant reductions in critical path risk and build early stakeholder confidence by securing the most essential elements. This targeted effort often allows other migration workstreams (like infrastructure setup or non-dependent data loading) to proceed in parallel while documentation for lower tiers continues.
2. Deploy Reverse-Engineering Tools with Proven ROI
Manually deciphering complex, undocumented legacy ETL logic is often time-consuming and prone to errors. Fortunately, specialized tools can dramatically accelerate this forensic process. Industry reports consistently highlight significant efficiency gains and substantial ROI when organizations deploy appropriate tooling for reverse-engineering and discovery during migrations.

Common effective tool categories include:
Static code analyzers: To parse and understand logic embedded within legacy scripts or stored procedures.
Metadata scrapers: To automatically discover and map data sources, table relationships, and dependencies across systems.
Data profiling tools: To analyze data distributions and patterns, helping infer hidden business rules or data quality standards.
Execution or runtime tracers: To capture transformation logic dynamically as it processes data in specific environments (where feasible).
Given the extremely high costs associated with project delays in large-scale migrations – often driven precisely by these documentation gaps – investing in the right reverse-engineering toolkit typically proves highly cost-effective, accelerating timelines and reducing overall migration risk.
3. Implement Documentation-as-Code in Your Modern Environment
To prevent documentation crises from recurring in modernized environments, the focus must shift to embedding documentation practices directly into the ETL development lifecycle. Leading approaches, often called "Documentation-as-Code" and aligned with CI/CD principles supported by industry bodies like DAMA (Data Management Association), treat documentation as a verifiable deliverable alongside code, leading to significantly fewer ongoing development and maintenance issues.
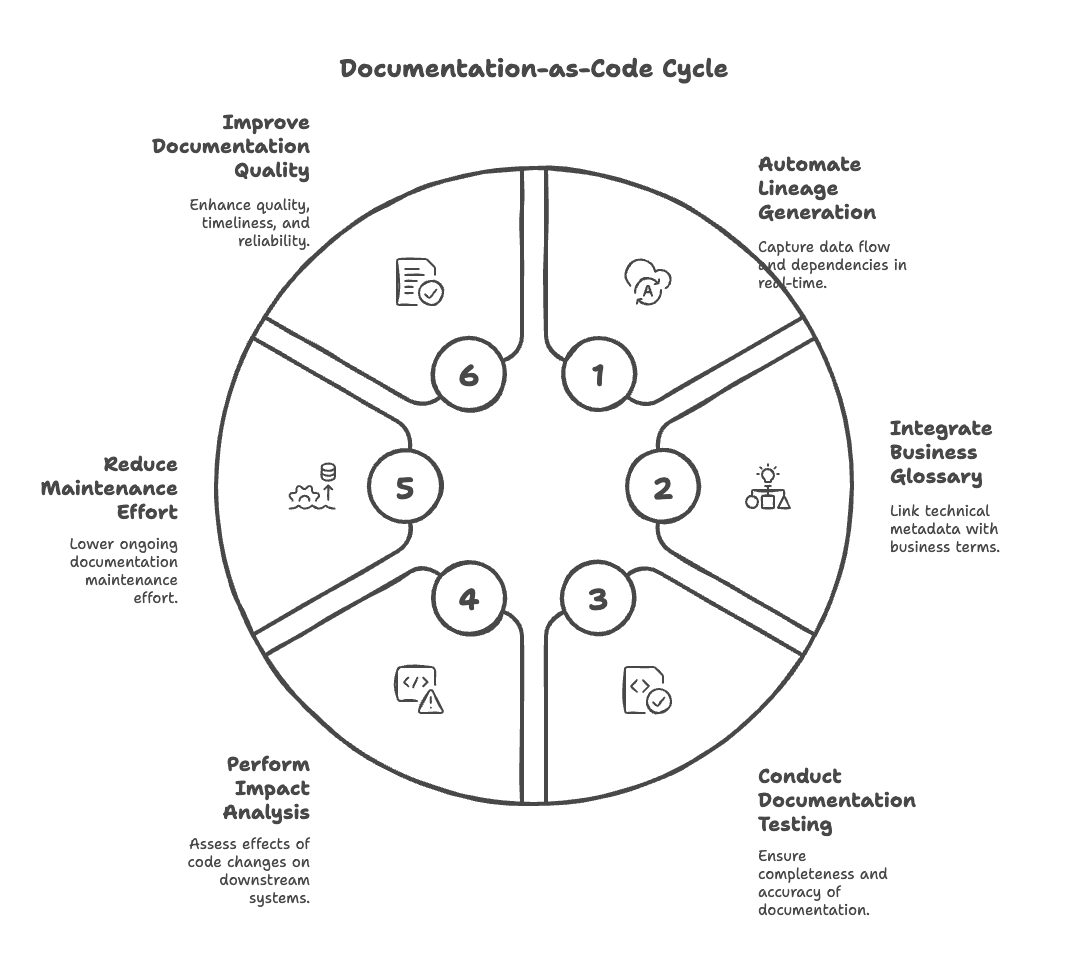
Key capabilities that enable this include:
Automated lineage generation: To continuously capture data flow, transformation dependencies, and usage in near real-time.
Business glossary integration: To automatically link technical metadata with agreed-upon business terminology, enhancing understanding.
Documentation testing: Incorporating checks for documentation completeness and accuracy within automated CI/CD testing suites.
Automated impact analysis: Tools that trace how proposed code changes might affect downstream systems or reports before deployment.
Implementing these practices, as seen in demanding environments like large retail group modernizations following previous migration challenges, demonstrably reduces ongoing documentation maintenance effort while simultaneously improving its quality, timeliness, and overall reliability.
Industry findings and practical experience consistently show that integrating documentation generation and validation into automated development pipelines is far more effective and sustainable for maintaining high-quality, trustworthy data lineage in the long term than traditional, often manual, and easily outdated documentation approaches.
That’s it for this week. If you found this helpful, leave a comment to let me know. ✊
PS...If you're enjoying Data Transformation Insights, please refer this edition to a colleague struggling with their modernization strategy. They'll thank you when they save thousands on their migration project.
About the Author
With 15+ years of experience implementing data integration solutions across financial services, telecommunications, retail, and government sectors, I've helped dozens of organizations implement robust ETL processing. My approach emphasizes pragmatic implementations that deliver business value while effectively managing risk.